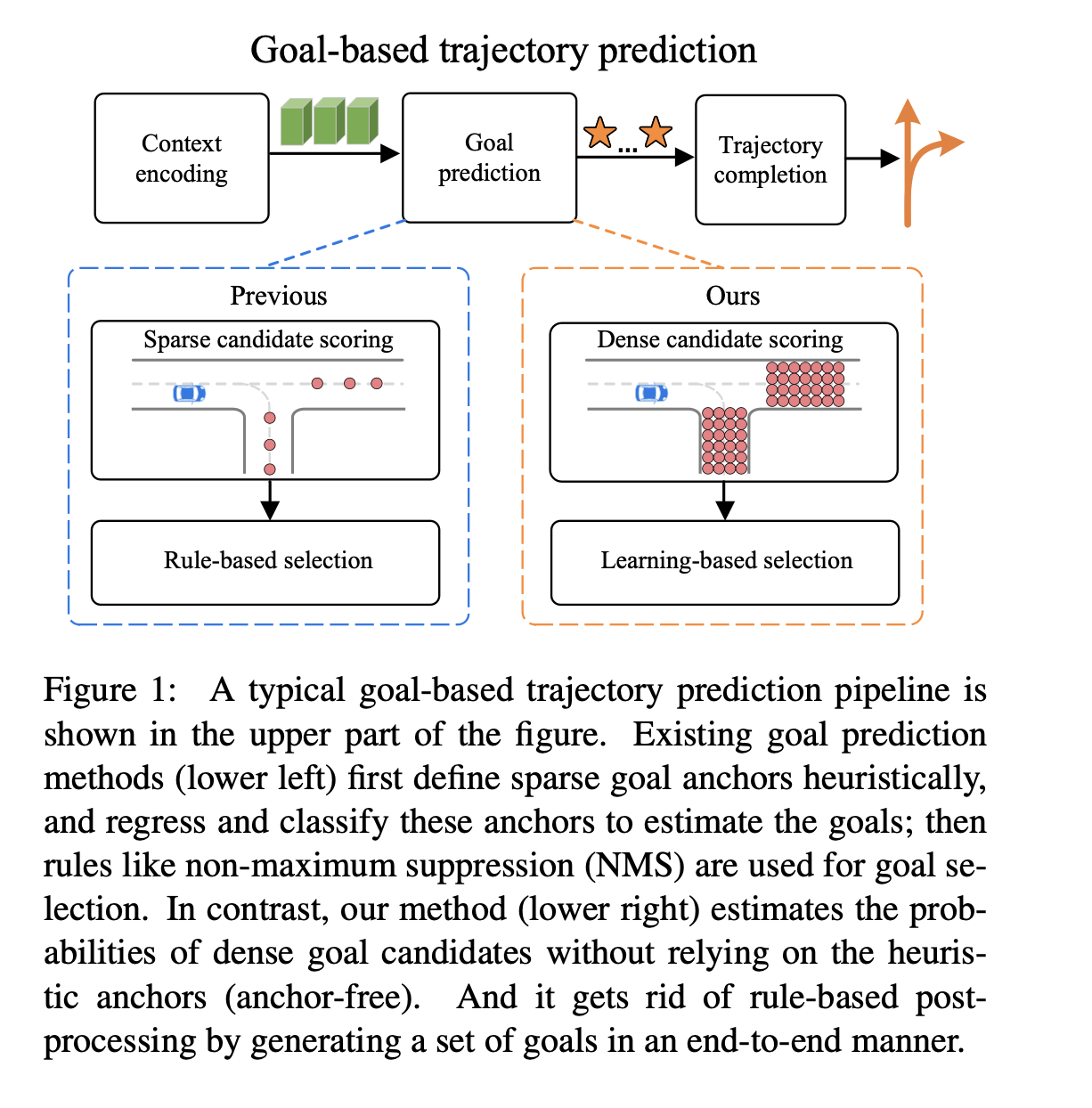
- 密集和稀疏概率分布区别
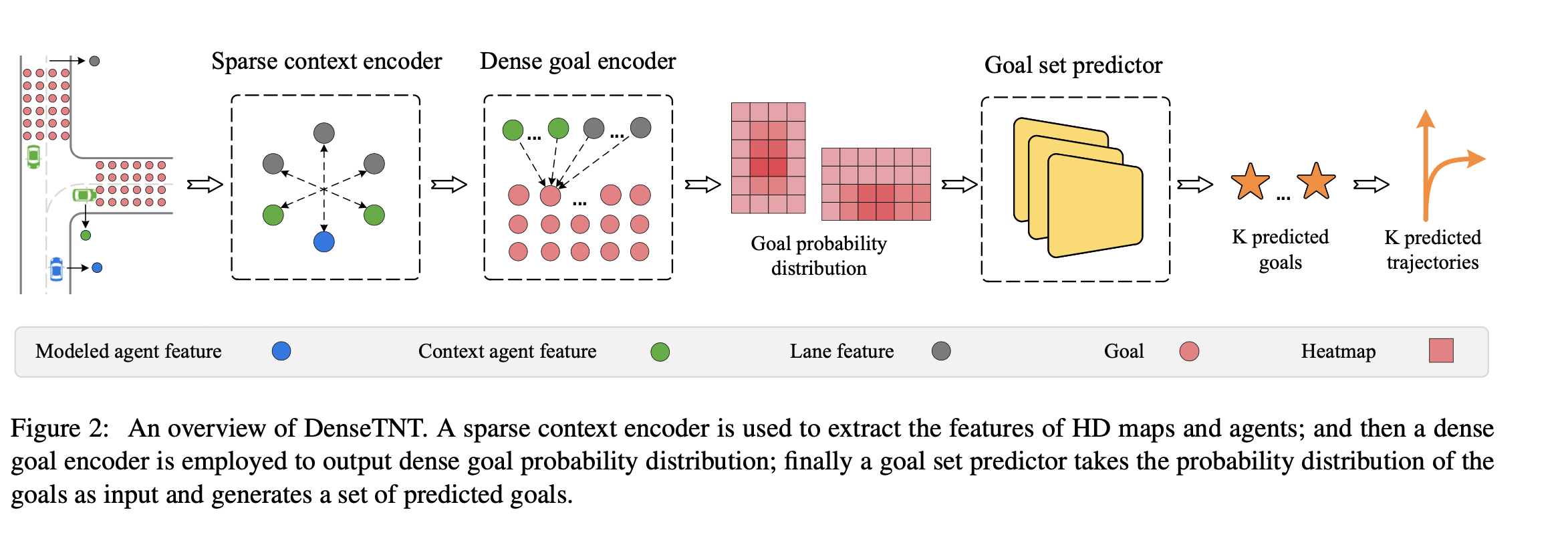
- Sparse context encoder:文章使用了vectorNet,VectorNet是一种分层图神经网络,由子图模块(subgraph module)和全局图模块(global graph module)组成。其中,子图模块用于编码车道(lanes)和交通参与者(agents)的特征,全局图模块 使用注意力机制来捕获车道和智能体之间的交互。在上下文编码后,我们获得一个二维特征矩阵 L,其中每一行 Li 表示第 i 个地图元素(即车道或智能体)的特征。
- Dense goal encoder: 它从车道特征中采样出密集的“目标”候选点(图示中红色圆点,表示大量密集分布的潜在目标位置)。然后,它使用注意力机制提取这些目标候选点与车道之间的局部信息 。最终,它输出目标概率分布 (Goal probability distribution),这通常表现为一个热图 (Heatmap) 。越深概率越高.
- 优化:在进行密集目标概率估计之前,DenseTNT 还会采用一个车道评分模块。目的: 这个模块旨在预测目标最终会落在哪个车道上。通过对车道进行评分,模型可以过滤掉那些不在候选车道上的目标候选点,从而减少后续计算量,提高效率 。车道评分被建模为一个分类问题,并使用二元交叉熵损失$L_{lane}$进行训练 。离真实目标最近的车道被赋予 1 的地面真值分数,其他为 0
- 训练损失: 密集目标编码器的训练(包括稀疏上下文编码器)通过一个二元交叉熵损失 $L_{goal}$ 进行监督。地面真值: 离最终真实位置最近的目标点的地面真值分数为 1,其他为 0 。
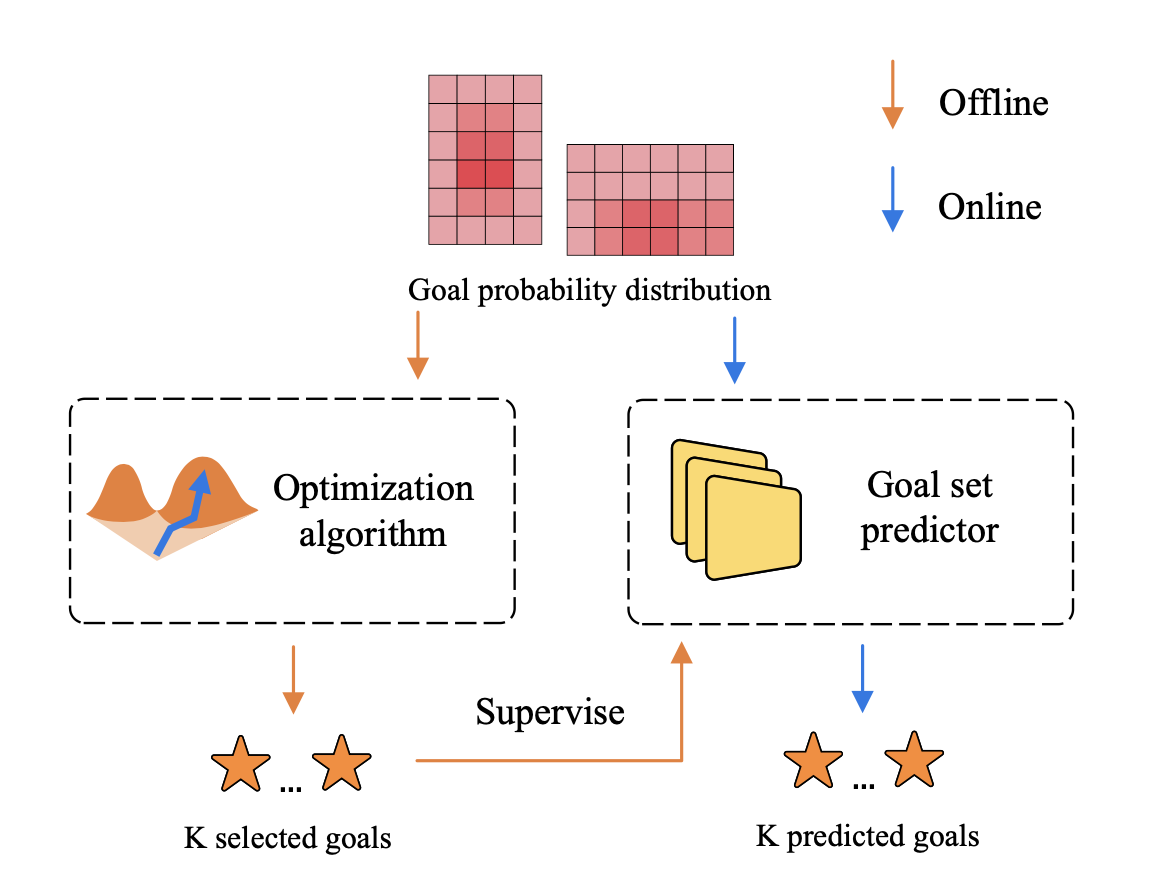
- Goal set predictor: 为了解决缺乏多标签监督和NMS的阈值难确定问题,DenseTNT 设计了一个离线模型来为在线模型(特别是目标集预测器)提供多未来伪标签 。离线模型包含与在线模型相同的编码模块,但用一个优化算法替代了目标集预测器 。
- 离线算法:热图输入: 离线模型从密集目标候选点 C={c1,c2,…,cm} 到 [0,1]⊂R 的映射 h 中获取热图,表示最终位置的概率分布 。目标函数: 离线模型的目的是找到一个目标集 y~,使其最小化预测目标集与真实目标位置随机变量 Y 之间的期望误差$f ( y )=\mathbb{E} [ d ( y, Y ) ]=\sum_{i=1}^{m} h ( c_{i} ) d ( y, c_{i} )$ 。这里的 $d ( \hat{y}, y_{g t} )$可以是最小最终位移误差(minFDE)$m i n_{y_{i} \in\hat{y}} | | y_{i}-y_{g t} | |$ 。优化算法: 论文采用了一种爬山算法(hill climbing algorithm)来迭代地寻找近似全局最优解 。 伪标签生成: 对于训练集中的每个样本,通过生成热图,然后使用此优化算法,可以获得一个最优的目标集 $\hat{y}$,它作为在线模型训练的伪标签 。 目标集预测器(在线模型)
-
集合预测: 类似于 DETR 将目标检测视为集合预测问题,DenseTNT 也将多未来预测视为集合预测问题 。 伪标签监督: 目标集预测器使用离线模型输出的伪标签 y^ 进行监督训练 。
- 训练策略:
-
与传统的匈牙利匹配不同,DenseTNT 在训练时进行离线优化,使用每个优化的伪标签来监督其对应的预测目标 。
-
具体来说,预测目标集$\dot{y}={\dot{y}{i} }{i=1}^{K}$ 在当前训练步骤生成后,离线优化算法会以 y˙ 作为初始目标集,并对其邻域进行搜索(随机扰动 L 次)以找到具有最低期望误差的伪标签 y^
-
-
多头设计: 目标集预测器包含多个预测头,以处理热图多样化的概率分布 。
-
每个头预测 2K+1 个值:K 个目标的 2D 坐标和该头的置信度 。
-
每个头由一个热图编码器(一层自注意力 + 最大池化)和一个解码器(两层 MLP)组成 。热图编码器的参数在所有头之间共享 。
-
-
置信度预测: 使用二元交叉熵损失${\cal L}{h e a d}={\cal L}{C E} ( \mu, \nu)$ 来预测多头的置信度 。对于具有最低期望误差的头,其置信度标签 νi=1,其他为 0 。
- 推理: 在推理时,选择具有最高置信度的头作为目标集预测器的输出 。
热图经过目标集预测器后,输出 K 个预测目标 (K predicted goals) ,用多个橙色星星表示。这些星星代表了模型认为最可能的 K 个未来终点。
轨迹补全 (Trajectory completion):
-
作用: 这是轨迹预测的最后一步,根据前一步预测出的 K 个目标,生成对应的完整未来轨迹
-
方法: 文章指出,该模块与 TNT 类似,通过一个解码器(2层 MLP)将每个目标特征转换为完整的轨迹序列 。
-
输出: 图示中,K 个预测目标 (橙色星星) 进一步转化为 K 个预测轨迹 (K predicted trajectories) ,用橙色线条表示。
Others
-
教师强制主要用于轨迹补全模块的训练 。它通过在训练时将真实的未来目标(地面真值)作为输入,帮助模型学习如何生成完整的轨迹序列 。这种方法确保模型在每一步都能接收到正确的上下文信息,从而加速训练并提高稳定性 。
-
伪标签监督则应用于目标集预测器的训练 。由于实际的轨迹预测任务通常只提供一个真实的未来轨迹作为地面真值(尽管可能存在多种合法的未来轨迹),这使得直接监督多模态预测变得困难 。伪标签监督通过一个离线优化算法,从密集的概率分布中推断出多个“最优”的未来目标集合作为伪标签,然后用这些伪标签来监督在线模型,使其能够预测多模态的未来轨迹 。
-
文章中损失的使用:
-
在第一阶段学习中,总损失 LS1 包含了车道损失 (Llane)、目标损失 (Lgoal) 和 轨迹补全损失 (Lcompletion) 。
- 车道损失和目标损失直接监督密集目标概率的估计。
- 轨迹补全损失在训练时使用了教师强制技术 。
-
在第二阶段学习中,总损失 LS2 包含了头部置信度损失 (Lhead) 和 目标集回归损失 (Lset) 。这些损失是用来监督目标集预测器,并利用了伪标签.
-
-