混合精度训练
 FP16 (Half-Precision):
FP16 (Half-Precision):
-
占用内存小(16 bits),可以节省显存空间,提升计算吞吐量。
-
缺点是表示范围较小,容易出现梯度下溢(underflow)和溢出(overflow)问题。
FP32 (Single-Precision):
-
占用内存相对较大(32 bits),但表示范围更广,数值更稳定。
-
通常用作权重的主存储格式,以避免数值不稳定。
混合精度训练的基本思想:
-
前向传播 (Forward Pass) 使用 FP16,以减少显存占用并提升吞吐量。
-
反向传播 (Backward Pass) 的梯度计算也使用 FP16,但在 更新权重 时仍然需要使用 FP32,以保证数值稳定性。
2. 混合精度训练的流程
如图片右侧的“Recipe for Mixed-Precision Training”所示,混合精度训练的主要步骤包括:
-
维持 FP32 的权重副本 (Master Weights):
- FP32 权重副本用于实际的权重更新,避免数值不稳定。
-
使用 FP16 进行前向传播 (Forward Pass):
- 将模型参数从 FP32 转换为 FP16,降低内存占用,提高计算速度。
-
缩放损失 (Loss Scaling):
- 将损失函数乘以一个较大的常数,以避免 FP16 精度较低导致的梯度下溢问题。
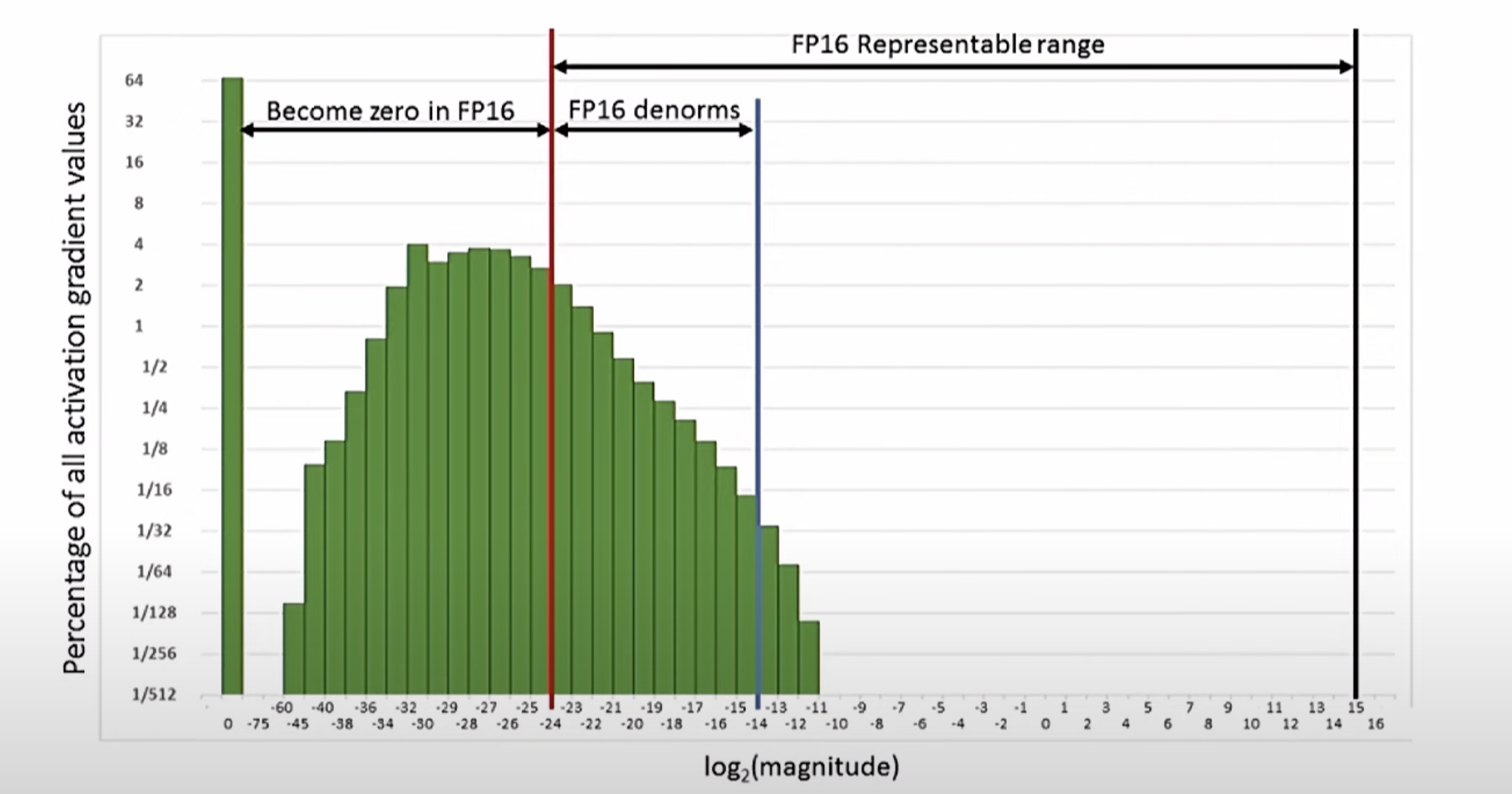
- 将损失函数乘以一个较大的常数,以避免 FP16 精度较低导致的梯度下溢问题。
-
FP16 梯度计算:
- 反向传播中的激活梯度和权重梯度都以 FP16 计算。
-
梯度缩放反转 (Unscale Gradients):
- 将缩放后的梯度还原,即将梯度除以前面的缩放因子,使得最终的梯度值与正常训练一致。
-
权重更新 (Weight Update):
- 使用 FP32 副本进行权重更新,确保数值稳定性。
-
权重同步:
- 将 FP32 副本的权重更新后,再转换为 FP16,用于下一轮计算
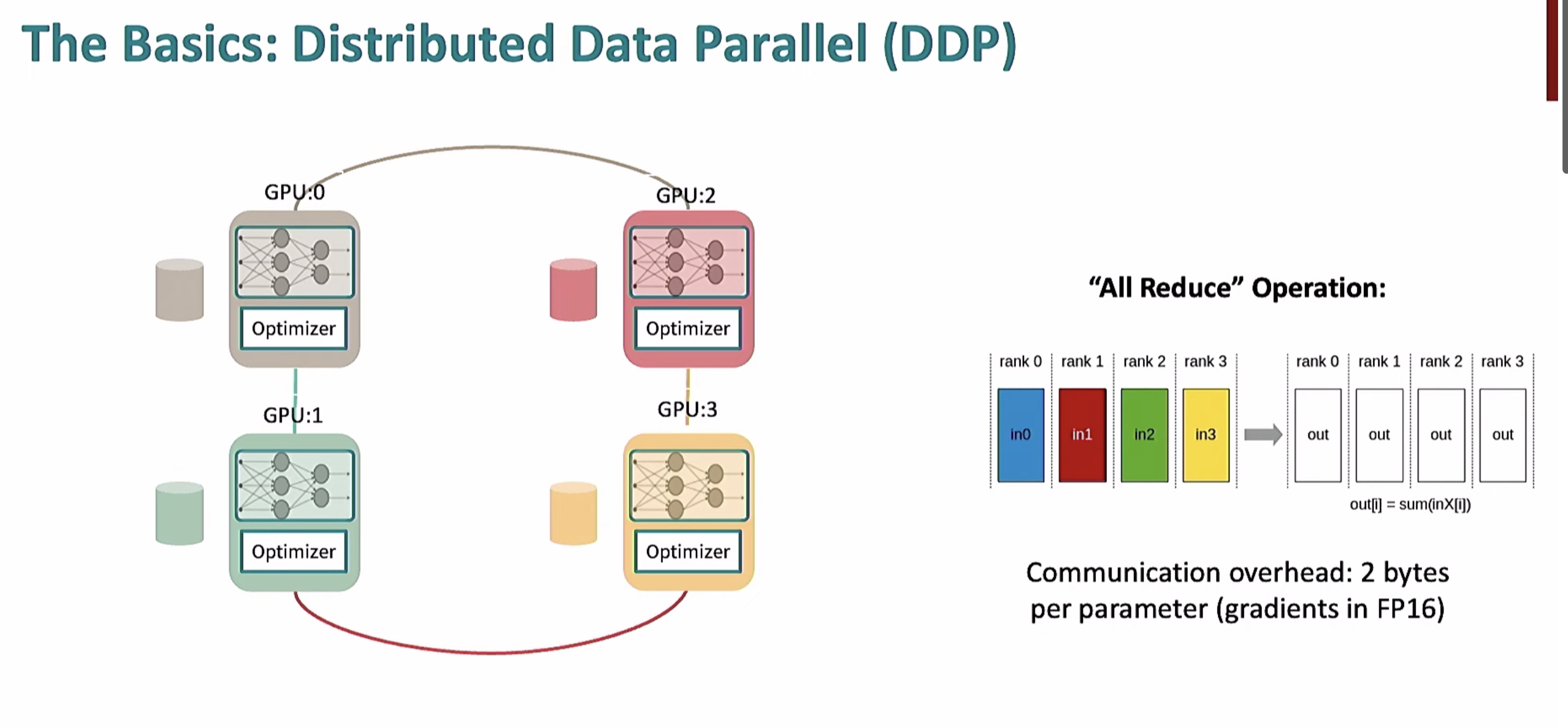
多GPU

- 将 FP32 副本的权重更新后,再转换为 FP16,用于下一轮计算
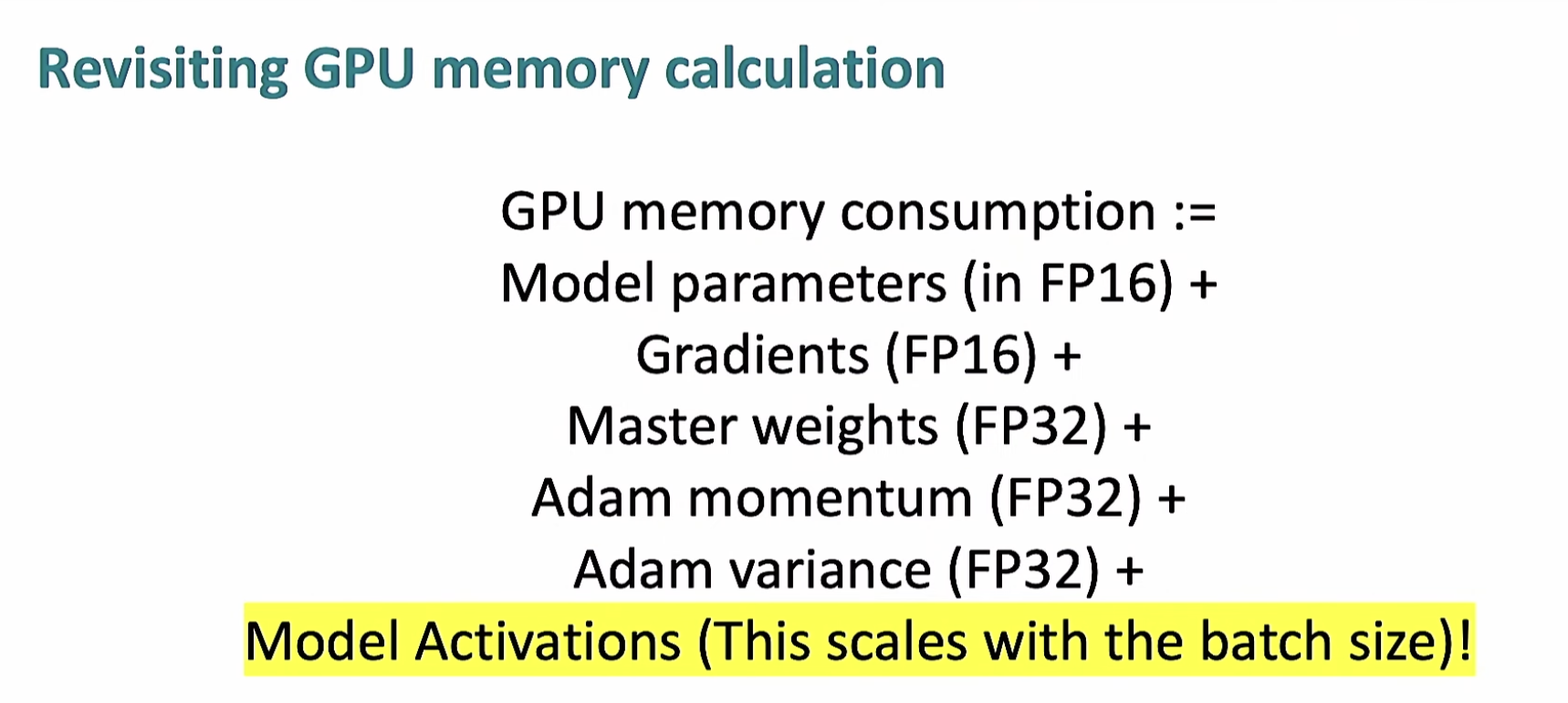
需要存储ADam,用FP32
zero
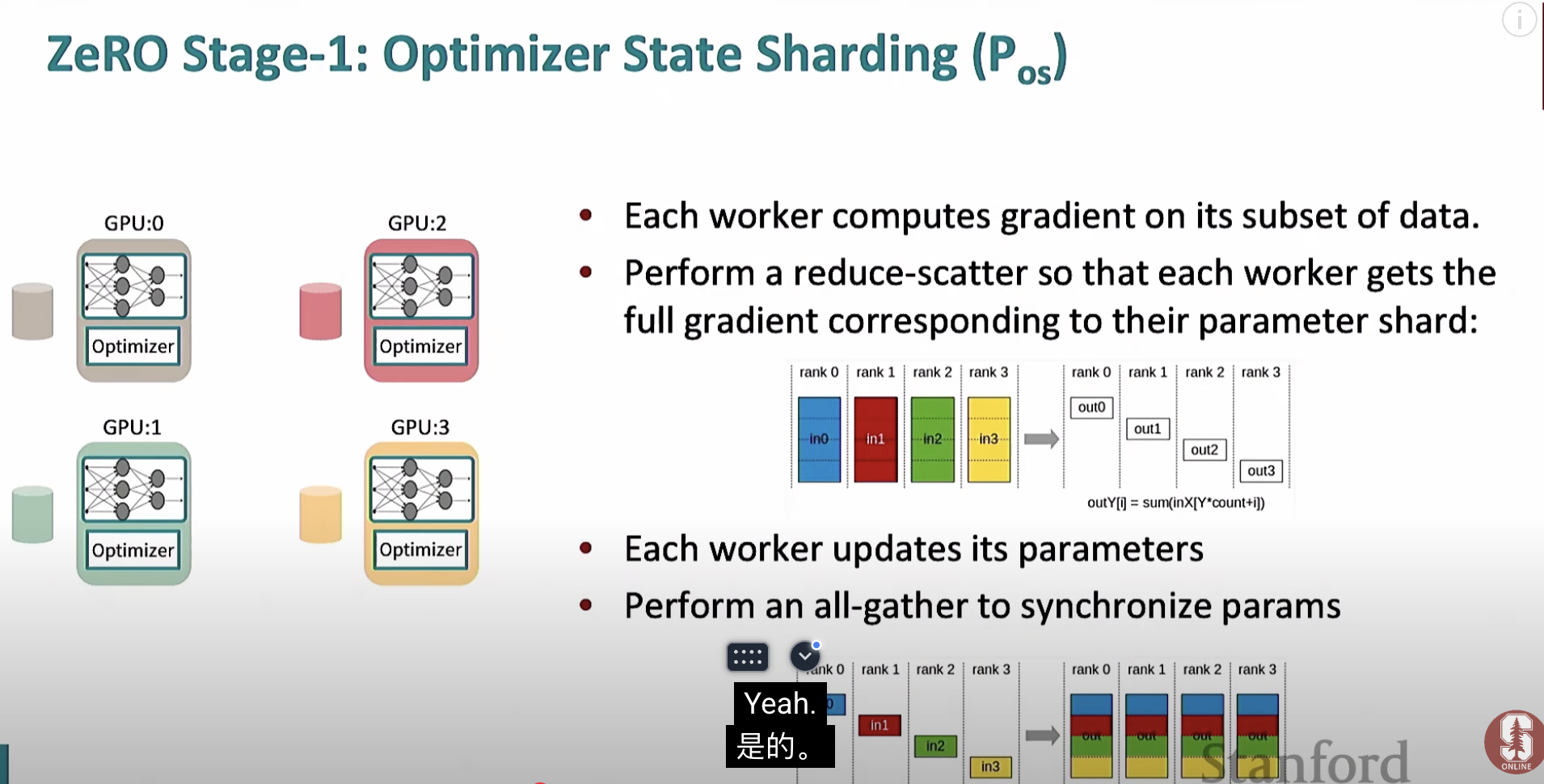
(1) 梯度计算
-
每个 GPU (Worker) 独立计算 自己的梯度,基于它分配到的小批量数据,例如:
-
GPU0 计算 in0
-
GPU1 计算 in1
-
GPU2 计算 in2
-
GPU3 计算 in3
-
(2) 梯度分片同步 (Reduce-Scatter)
-
目的:
- 每个 GPU 只需要保留部分全局梯度,不需要完整的梯度矩阵,从而减少显存占用。
-
过程:
-
每个 GPU 计算的局部梯度被分片 (Shard),并通过 Reduce-Scatter 进行同步。
-
例如:
-
Rank 0 (GPU0) 最终得到 out0 (包含全局梯度的一部分)
-
Rank 1 (GPU1) 得到 out1
-
Rank 2 (GPU2) 得到 out2
-
Rank 3 (GPU3) 得到 out3
-
-
公式:$out_{i}= sum(inX^{Y * count + i})$,其中 Y 是每个 GPU 分片数量。
-
(3) 参数更新
- 每个 GPU 使用它本地的优化器状态和收到的梯度分片进行参数更新。
(4) 参数同步 (All-Gather)
-
目的:
- 将每个 GPU 的参数更新结果在所有 GPU 之间同步,以确保每个 GPU 具有相同的全局模型参数。
-
过程:
-
每个 GPU 只保留自己负责的参数 shard,并通过 All-Gather 将这些 shard 重新组合,形成完整的模型参数。
-
这确保了下一个前向传播阶段,每个 GPU 都有相同的模型权重。
-
ZeRO (Zero Redundancy Optimizer) 三个阶段详解
ZeRO 是 DeepSpeed 中的核心技术之一,其主要目标是优化内存使用,使得超大规模模型在现有硬件资源上可以进行高效的并行训练。ZeRO 分为三个主要阶段,每个阶段都进一步优化了模型的存储和计算效率:
📝 1. ZeRO Stage-1: 优化优化器状态 (Optimizer States)
🔹 核心思想:
-
仅对优化器状态 (Optimizer States) 进行切分。
-
每个 GPU 只持有本地负责参数的优化器状态,而不是整个模型的所有状态。
🔹 主要优化对象:
-
优化器状态包括:
-
权重梯度 (Gradients)
-
动量 (Momentum)
-
二阶矩 (RMS, Adam 变体)
-
🔹 内存优化效果:
-
对于 Adam 优化器,优化器状态大约占用模型参数的 4 倍内存。
-
通过切分优化器状态,可以减少 75% 的显存占用。
🔹 工作流程:
-
前向传播:
- 计算激活值,但不涉及优化器状态。
-
反向传播:
- 每个 GPU 计算本地持有参数的梯度。
-
梯度聚合:
- 所有 GPU 在此阶段会通过All-Reduce同步梯度。
-
参数更新:
- 每个 GPU 只更新自己负责的优化器状态。
🔹 适用场景:
- 中等规模模型,例如 BERT 大小的模型。
📝 2. ZeRO Stage-2: 优化梯度 (Gradients)
🔹 核心思想:
-
在 Stage-1 的基础上进一步切分权重梯度 (Gradients)。
-
每个 GPU 只保存自己负责的参数梯度,减少梯度同步开销。
🔹 主要优化对象:
-
优化器状态 (Optimizer States)
-
权重梯度 (Gradients)
🔹 内存优化效果:
-
对于 Adam 优化器,可以减少模型参数 8 倍左右的内存 (包含状态和梯度)。
-
进一步降低了显存占用,使得更大模型可以并行训练。
🔹 工作流程:
-
前向传播:
- 每个 GPU 只持有自己负责的参数,不存储完整模型。
-
反向传播:
- 计算本地梯度,不需要在反向计算过程中存储完整的权重梯度。
-
梯度同步:
- 通过Reduce-Scatter同步梯度,减少通信开销。
-
参数更新:
- 每个 GPU 只更新自己负责的梯度和优化器状态。
🔹 适用场景:
- 大模型,例如 GPT-3 规模的模型。
📝 3. ZeRO Stage-3 (FSDP): 完全分片 (Fully Sharded Data Parallel)
🔹 核心思想:
-
全面分片,不仅仅是优化器状态和梯度,还包括模型参数 (Model Parameters)。
-
这是最完整的分片策略,进一步减少内存占用。
🔹 主要优化对象:
-
优化器状态 (Optimizer States)
-
权重梯度 (Gradients)
-
模型参数 (Model Parameters)
🔹 内存优化效果:
- 对于 Adam 优化器,可以将显存需求减少到原始模型的 1/N (N 是 GPU 数量),使得超大规模模型的训练成为可能。
🔹 工作流程:
-
前向传播:
- 每个 GPU 只持有部分参数,并在需要时执行All-Gather聚合。
-
反向传播:
- 梯度计算后立即释放参数,并将梯度分散到各 GPU (Reduce-Scatter)。
-
参数更新:
- 仅本地持有的参数进行更新,不需要同步全量参数。
-
动态内存优化:
- 使用更高效的内存释放策略,进一步优化显存利用。
🔹 适用场景:
- 超大规模模型 (例如 GPT-4, PaLM, LLaMA),需要在数千个 GPU 上进行分布式训练
ZeRO (Zero Redundancy Optimizer) 是一种用于分布式深度学习的高效优化策略,主要目的是减少 GPU 显存占用,实现超大模型的高效训练。ZeRO 有三个阶段,其中 Stage-3 是最完整的实现,包含了 FSDP (Fully Sharded Data Parallel) 机制,可以显著降低内存占用,同时提升训练效率。
一、FSDP 机制核心思想
FSDP 的核心是 全量参数分片,即将模型的 参数 (Weights)、优化器状态 (Optimizer States) 和 梯度 (Gradients) 进行完整的切分,并在所有 GPU 设备之间均匀分布,主要包括以下几个关键步骤:
-
模型参数切分 (Divide Model Parameters)
-
将模型划分为多个 FSDP Units(例如图中的 0, 1, 2 等),每个 FSDP Unit 代表模型的一部分参数和计算逻辑。
-
每个 FSDP Unit 可以包含一个完整的神经网络层或多个连续层,具体划分视模型结构而定。
-
-
跨 GPU 分片 (Shard Each Unit Across Multiple GPUs)
- 每个 FSDP Unit 被进一步切分,并分布到多个 GPU 上,确保每个 GPU 只持有部分参数,减少显存占用。
二、FSDP 计算流程
FSDP 的计算流程主要分为 前向传播 (Forward Pass)、反向传播 (Backward Pass) 和 参数更新 (Parameter Update),具体如下:
1. 前向传播 (Forward Pass)
-
参数聚合 (All-Gather, AG)
-
在执行每个 FSDP Unit 的前向计算之前,需要将分布在不同 GPU 上的参数临时收集到一起。
-
这个过程通过 All-Gather 完成,具体流程如下:
-
AG0: GPU 0 收集它负责的 FSDP Unit 0 的全部参数。
-
AG1: GPU 1 收集 FSDP Unit 1 的全部参数,以此类推。
-
-
-
前向计算 (FWD)
-
一旦参数聚合完成,各 GPU 开始执行对应 FSDP Unit 的前向计算:
-
FWD0: GPU 0 计算 FSDP Unit 0 的前向传播。
-
FWD1: GPU 1 计算 FSDP Unit 1,以此类推。
-
-
释放内存: 前向传播结束后,可以立即释放聚合的模型参数,减少内存占用。
-
2. 反向传播 (Backward Pass)
-
梯度计算 (BWD)
-
每个 GPU 基于前向计算得到的中间激活值,计算对应 FSDP Unit 的反向梯度:
-
BWD0: GPU 0 计算 FSDP Unit 0 的梯度。
-
BWD1: GPU 1 计算 FSDP Unit 1,以此类推。
-
-
-
梯度分散 (Reduce-Scatter, RS)
-
由于梯度需要在多个 GPU 之间同步,因此需要将计算得到的梯度重新分散到各自的 GPU 上:
-
RS2: GPU 2 将计算得到的梯度分散到其他 GPU。
-
RS1: GPU 1 同样执行梯度分散。
-
RS0: GPU 0 执行梯度分散。
-
-
3. 参数更新 (Parameter Update)
-
每个 GPU 在完成梯度分散后,仅更新自己持有的参数分片:
- 例如,GPU 0 只更新 FSDP Unit 0 的参数,GPU 1 只更新 FSDP Unit 1 的参数。
-
这样做的好处是显著减少了参数同步的开销,并且大大降低了显存占用。
三、数据流与计算流的并行 (Stream Overlap)
-
计算流 (GPU Comp. Stream):
- 负责模型前向、反向计算 (FWD, BWD)。
-
通信流 (GPU Comm. Stream):
- 负责参数的聚合 (AG)、梯度分散 (RS)。
-
并行优化:
- 通过在计算流和通信流之间实现并行,可以显著减少计算瓶颈,提高整体训练效率。
四、内存优化策略
-
Parameter Free 区域:
- 在反向传播结束后,FSDP 可以立即释放对应的模型参数,减少不必要的显存占用。
-
Sharding 优化:
- 只存储本地 GPU 负责的参数,减少了每个 GPU 的显存压力
PEFT
PEFT 的核心思想是只微调模型的一小部分参数,而不是整个模型。
