Motivation
- 目前的大多数方法都基于大量的标签数据进行训练,然后在一些的城市场景内的数据存在缺失性,我们需要构建一个泛化性强的时空大模型来进行优化流量,减少拥堵,提高移动性
- 目前的模型,如llama对于复杂的时空关系难以处理,对于baseline model, 他很容易出现overfit 在zero-shot 场景
- 文章通过将时空依赖编码器(spatio-temporal dependency encoder)与指令调优范式(instruction-tuning paradigm)无缝集成来实现将时空上下文与LLMs对齐。
example
Method

Spatio-Temporal Dependency Encoder
时空编码器由两个关键组件组成:门控扩张卷积层(gated dilated convolution layer)和多层相关性注入层(multi-level correlation injection layer)。让我们将此架构形式化为:
\(\mathbf{\Psi}_r^{(l)}=(\bar{\mathbf{W}}_k^{(l)}*\mathbf{E}_r^{(l)}+\bar{\mathbf{b}}_k^{(l)})\cdot\delta(\bar{\mathbf{W}}_g^{(l)}*\mathbf{E}_r^{(l)}+\bar{\mathbf{b}}_g^{(l)})+\mathbf{E}_r^{\prime(l)}\)
原始数据X通过线性层增强输出时空嵌入$E𝑟 \in R^{𝑇×𝑑}$,为了解决梯度消失(gradient vanishing)问题,我们利用E𝑟的一个切片,记为$E′𝑟 \in R^{𝑇’×𝑑}$,该切片的大小由空洞卷积核(dilated convolutional kernel)的大小决定。该切片用于执行残差操作(residual operations)。为了执行残差操作,我们使用一维空洞卷积核W𝑘和W𝑔 ∈$R^{𝑇𝑔×𝑑𝑖𝑛×𝑑𝑜𝑢𝑡}$,以及相应的偏置项b𝑘和b𝑔 ∈$R^{𝑑𝑜𝑢𝑡}$。Sigmoid激活函数𝛿用于控制重复卷积操作期间的信息保留程度。经过门控时序空洞卷积层(gated temporal dilated convolutional layer)编码后,我们能够有效地捕获跨多个时间步长的时间依赖关系,从而生成时间表示(temporal representations)。
为了保留这些信息丰富的模式,我们引入了一个多层级相关性注入层(multi-level correlation injection layer)。该层旨在整合不同层级之间的相关性,并形式化为:
\(\mathbf{S}_r^{(l)}=(\mathbf{W}_s^{(l)}*\mathbf{\Psi}_r^{(l)}+\mathbf{b}_s^{(l)})+\mathbf{S}_r^{(l-1)}\)
convolution kernel $\mathbf{W}s\in\mathbb{R}^{T_S\times d{out}\times d_{out}^{\prime}}$ and the bias vector $\mathbf{b}_s\in\mathbb{R}^{d^{\prime}\text{out}}.$ 最终的时空依赖表示$\tilde{\Psi}\in\mathbb{R}^{R\times F\times d}$
为了应对下游可能出现的各种城市场景,我们提出的时空编码器在建模空间相关性时,被设计为独立于图结构(graph structures)。这一点至关重要,因为在零样本预测(zero-shot prediction)的情况下,实体间的空间关系可能是未知的或难以确定。通过不依赖显式的图结构,我们的编码器能够有效地处理广泛的城市场景,在这些场景中,空间相关性和依赖关系可能会变化,或者难以提前定义。这种灵活性使我们的模型能够适应并表现良好,从而确保其在各种城市环境中的适用性。
Spatio-Temporal Instruction-tuning
时空文本对齐 (Spatio-Temporal-Text Alignment)。为了使语言模型能够有效地理解时空模式,至关重要的是对齐文本和时空信息。这种对齐允许不同模态的融合,从而产生更具信息量的表示。通过整合来自文本和时空领域的上下文特征,我们可以捕获互补信息,并提取更具表现力和意义的更高层次的语义表示。
为了实现这一目标,我们利用一个轻量级对齐模块来投影时空依赖关系表示 Ψ。此投影涉及使用参数 $W𝑝 ∈R^{𝑑×𝑑_{L}}$ 和 b𝑝 ∈R𝑑𝐿,其中 𝑑𝐿 表示语言模型 (LLMs) 中常用的隐藏维度。产生的投影,记为 $H \in R^{𝑅×𝐹×𝑑_{𝐿}}$,在指令中用特殊标记(special tokens)表示为:, , ..., , 。其中, 和 用作标识符,标记时空令牌(spatio-temporal token)的开始和结束。通过扩展大规模语言模型的词汇表,可以将这些标识符包含在其中。 占位符代表时空令牌,对应于隐藏层中的投影 H。通过采用这种技术,模型能够辨别时空依赖性(spatio-temporal dependencies),从而提高其在城市场景中成功执行时空预测任务(spatio-temporal predictive tasks)的能力。
-
标记对应于通过时空依赖编码器(Spatio-Temporal Dependency Encoder)生成的时空依赖表示,包含了历史数据中的时间和空间依赖信息。
- 对齐时空与文本:通过将历史时空数据嵌入到 LLM 的语义空间, 帮助模型理解历史数据中的时空动态,并结合文本指令进行推理。
是用来表示预测时空数据的标记,主要用于在指令调整过程中生成预测结果的中间表示(预测标记),这些标记随后通过回归层映射为具体的数值预测。
- **生成预测标记**: 是 LLM 在指令调整后生成的预测标记,代表未来时间步的时空数据(如未来的出租车流入量和流出量)。
- **桥接 LLM 和数值预测**:由于 LLM 擅长处理分类任务(预测词汇的概率分布),而时空预测通常需要连续值(如流量值), 作为中间表示,结合回归层解决这一问题。
- 在时空指令调整阶段,LLM 接收包含 的历史数据和文本指令(如时间、区域信息),生成预测标记 。
```
: [44 23 41 32 53 95 68 0 101 117] # 流入预测标记
: [64 22 41 32 43 95 68 0 100 115] # 流出预测标记
```
### Spatio-Temporal Prompt Instructions
在涉及时空预测的场景中,时间和空间信息都包含有价值的语义细节,这些细节有助于模型理解特定环境中的时空模式。例如,清晨的交通流量与高峰时段明显不同,商业区和住宅区之间的交通模式也存在差异。
在我们的UrbanGPT框架中,我们将多粒度的时间信息和空间细节整合为大型语言模型的指令输入。时间信息包括星期几和一天中的具体时间,而区域信息则涵盖城市、行政区域以及附近的兴趣点(POI)数据等等。通过整合这些不同的要素,UrbanGPT 能够识别和同化不同地区和时间范围内的时空模式(spatio-temporal patterns)。这使得该模型能够将这些洞察力封装在复杂的时空背景中,从而提高其零样本推理(zero-shot reasoning)能力。

### Spatio-Temporal Instruction-Tuning of LLMs
使用指令对大型语言模型(LLMs)进行微调,以生成文本格式的时空预测。然而,这种方法存在两个挑战。首先,时空预测通常依赖于数值数据,其结构和模式与自然语言不同,而语言模型擅长处理自然语言,侧重于语义和句法关系。其次,大型语言模型通常使用多分类损失进行预训练,以预测词汇,从而产生潜在结果的概率分布。这与回归任务所需的连续值分布形成对比。
为了应对这些挑战,UrbanGPT 采取了一种不同的策略,即避免直接预测未来的时空值(spatio-temporal values)。取而代之的是,它生成预测令牌(forecasting tokens)来辅助预测过程。这些令牌随后被传递到一个回归层(regression layer),该回归层映射隐藏表示(hidden representations)以生成更准确的预测值。
$$\hat{\mathbf{Y}}_{r,f}=\mathbf{W}_3[\sigma(\mathbf{W}_1\mathbf{H}_{r,f}),\sigma(\mathbf{W}_2\mathbf{\Gamma}_{r,f})]$$
这边使用了隐藏层表征捕捉动态的时空相互依赖关系,提高预测准确性
## Model Optimization
我们采用绝对误差损失(absolute error loss)作为回归损失函数。 此外,我们引入分类损失作为联合损失以满足多样化的任务需求。 为了确保最佳性能,我们的模型根据特定任务的输入优化不同的损失函数。 例如,我们利用回归损失来处理诸如交通流量预测之类的任务,而采用分类损失来处理诸如犯罪预测之类的任务。 这种方法使我们的模型能够有效地应对每个任务带来的独特挑战,并在各种城市场景中提供准确的预测。
$$\mathcal{L}_{c}=-\frac{1}{N}\sum_{i=1}^N\left[\delta(y_i)\cdot\log(\hat{y}_i)+(1-\delta(y_i))\cdot\log(1-\hat{y}_i)\right]$$
$$\mathcal{L}_{r}=\frac{1}{N}\sum_{i=1}^N|y_i-\hat{y}_i|;\quad\mathcal{L}=\mathcal{L}_{LLMs}+\mathcal{L}_r+\mathcal{L}_c$$
这边的yi是sample,N是sample个数,$\mathcal{L}_{c}$为二分交叉熵,$\mathcal{L}_{r}$为回归损失,$\mathcal{L}_{LLMS}$时空语言模型中采用的交叉熵损失。
## Evaluation
在本节中,我们旨在通过解决以下五个关键问题,评估我们提出的模型在各种设置下的能力:
•RQ1:UrbanGPT 在各种零样本时空预测任务中的性能和泛化能力如何?
•RQ2:在经典监督场景中,与现有的时空模型相比,UrbanGPT 的表现如何?
•RQ3:所提出的关键组成部分为提升我们的 UrbanGPT 模型的能力带来了哪些具体贡献?
•RQ4:所提出的模型能否稳健地处理具有不同时空模式的预测场景?
实验分为两种场景:
- **零样本学习场景 (Zero-Shot Learning Scenarios)**:
- 目标:在未见区域(NYC 内)或未见城市(芝加哥,CHI-taxi)上进行预测。
- 方法:从 NYC 数据集中选择部分区域作为训练集,剩余区域或 CHI-taxi 数据作为测试集。
- **监督学习场景 (Supervised Learning Scenarios)**:
- 目标:在训练区域的未来时间段进行预测。
- 方法:使用同一区域的历史数据训练模型,测试其在未来时间段的预测能力。
#### **基线模型 (Baseline Models)**
实验比较了 UrbanGPT 与 10 个先进的基线模型,分为三类:
- **RNN-based 方法**:
- AGCRN、DMVSTNET、ST-LSTM:利用循环神经网络(RNN)捕捉时间依赖。
- **GNN-based 方法**:
- GWN、MTGNN、STSGCN、TGCN、STGCN:利用图神经网络(GNN)捕捉空间相关性,结合时间编码器建模时空关系。
- **Attention-based 方法**:
- ASTGCN、STWA:利用注意力机制建模时空相关性。
- **UrbanGPT**:基于 Vicuna-7B 模型构建,结合时空依赖编码器和指令调整范式。
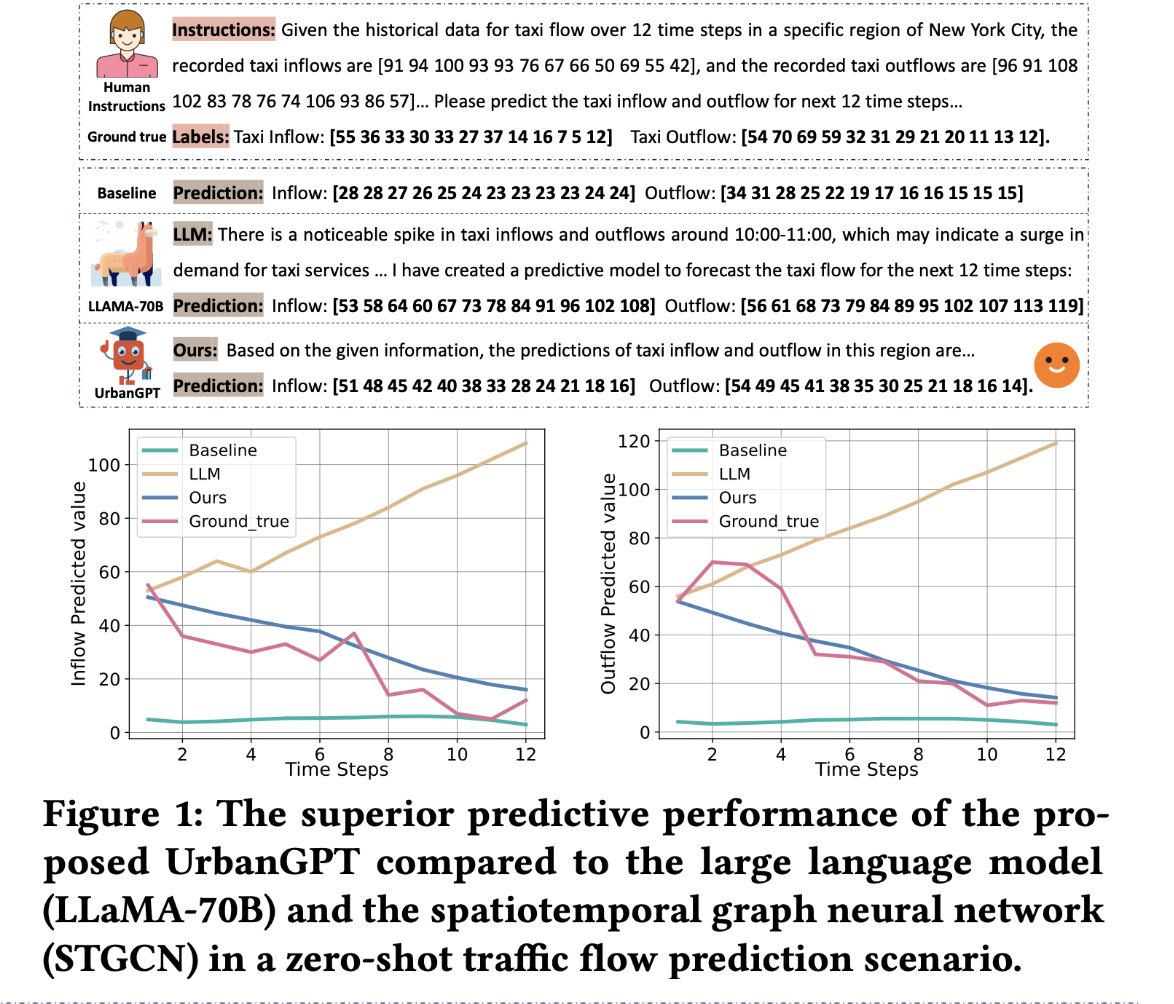
#### 零样本预测性能 (RQ1: Zero-Shot Prediction Performance)

UrbanGPT 性能最好
#### 跨城市预测 (Cross-City Prediction Task)
- **目标**:在未见城市(CHI-taxi)上进行预测,测试模型的知识迁移能力。
- UrbanGPT 在 CHI-taxi 数据集上表现优于基线模型。
- **多步预测一致性**:在短时和长时预测中,UrbanGPT 的误差始终低于基线,展现了鲁棒性。
- **有效知识迁移**:模型能够捕捉可转移的时空模式,并在不同城市间关联相似的功能区域(如商业区)。